| 記述統計学の概念 | ||||
| 記述統計学 | ||||
| 記述統計学とは 全数調査から得た資料を整理してその内容を特徴づける各種の数値(平均,標準偏差,メジアン,モード,相関係数等)を算出し,それにより観察された集団の性質を記述する統計学。 記述統計学の特徴 観察対象となる集団の性質(特徴)・傾向(ばらつき)を正確に記述することを目的とする統計学である。 記述統計学では、サンプルの個別的なデータを数量化(数値化)して取り扱いながら集団の性質(特徴)を記述していく。 データを質的に捉えるのではなく量的に捉えるところに科学的学問としての特徴がある。大量のデータの観察と数量化によって集団の特徴をコツコツと記述するのが記述統計学であるが、最も初期に発達したのが記述統計学である。 |
||||
| 記述統計学の目的 | ||||
| 記述統計学の目的 収集したデータの要約統計量(平均、分散など)を計算して分布を明らかにする事により、データの示す傾向、性質、規則性を知ること。 すなわち、データの要約を行うこと。 |
||||
| 要約統計量 | ||||
| 記述統計量、基本統計量、代表値ともいう。 正規分布の場合 平均と、分散または標準偏差で分布を記述できる。 正規分布からのずれを知るためには、尖度や歪度などの高次モーメントから求められる統計量を用いる。 正規分布から著しく外れた場合 より頑健な中央値、四分位点、最大値・最小値や最頻値が用いられる。 「頑健」とは分布の非対称性や外れ値などの影響を受けにくいことを意味する統計用語である。 例えば、労働者一人あたりの年収を例に採れば、最も収入が少なくても0未満にはならないのに対し、収入が多いほうでは数十億円という年収を稼ぐ少数者があり得る。 この場合の分布は、少数者が上側にいることによって、上側に極端に尾を引いた非対称な分布となる。 平均値はこれらの極端な高値の影響を受け、分布の代表値として適切でないものとなってしまう。 中央値や最頻値では、いかに飛び抜けた値であっても1例としてしか扱われないので、より大多数の実感に近い値を示すことができる。 |
||||
| 要約統計量 | ||||
| 平均(mean、ミュー μ) | ||||
| (1)相加平均(算術平均) 単に「平均」と言うときは、この僧か平均(算術平均)を指す。 観測されるデータから、その散らばり具合を "平らに均す(ならす)" 事によって得られる統計的な指標。 平均=データの総和÷個数 μ=(X1+X2+・・・・+Xn)÷n (2)相乗平均(幾何平均) (3)加重平均 |
||||
| 分散(variance、シグマ σ) | ||||
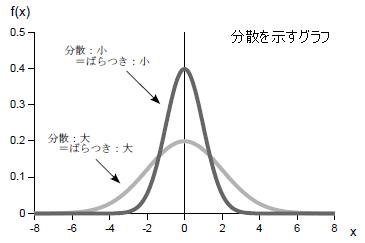
| データのばらつきを表す値のこと。 データのばらつきが大きいほど分散は大きく、ばらつきが小さいほど分散は小さくなる。 個々のデータと平均値の差を求め、値をそれぞれ2乗し、それらを合計したものをデータの個数で割ることによって求められる。 対象のデータによって、次の3つの分散がある。 1:母集団の分散を表す母分散(母集団分散) 2:標本から母集団の分散を推定する際に用いる不偏分散 3:標本自身の分散を表す標本分散 |
||||
|
||||
| (1)母分散(母集団分散) 母分散は母集団のばらつきの大きさを示す統計量。 対象となるデータを母集団の標本(母集団から任意に取り出したデータの集まり)とみなして、母集団の分散を求める。 ここで、Eは期待値を表す。 (2) 不偏分散 標本から母集団の分散を推定するために用いるのが、不偏分散。 n-1で割ることで、不偏性を持った不偏推定量になる。  (3) 標本分散(sample variance) 標本自体の分散。標本自体のばらつきの大きさを表す。 標本分散は、その期待値が母分散(母集団の分散)よりも若干小さくなることが知られている。  |
||||
| 標準偏差(sutandard deviation、SD) | ||||
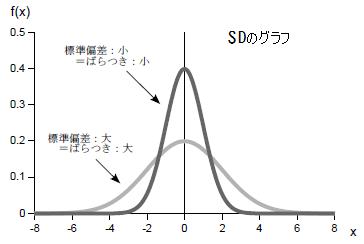
| 標準偏差とは、データのばらつきの大きさを表す統計量です。 データのばらつきが大きいほど標準偏差は大きく、ばらつきが小さいほど標準偏差は小さくなる。 対象のデータによって、次の3つの標準偏差があります。 1:母集団の標準偏差を表す母標準偏差 2:標本から母集団の標準偏差を推定する際に用いる不偏標準偏差 3:標本自身の標準偏差を表す標本標準偏差 |
||||
|
||||
| 1:母標準偏差 母集団のばらつきの大きさを示す統計量で、無限母集団か有限母集団かによって、それぞれ次の式で表さる。 無限母集団の母標準偏差  μは母集団の平均、f(x)は母集団の確率密度関数 μは母集団の平均、f(x)は母集団の確率密度関数有限母集団の母標準偏差  Xiは各データの値、Piは各データの出現確率、X barは母集団の平均 Xiは各データの値、Piは各データの出現確率、X barは母集団の平均(2)不偏標準偏差 標本から母集団の標準偏差を推定するために用いる。 n-1で割ることで、不偏性を持った不偏推定量になる。  nはデータの個数、xiは各データの値、x barは標本平均 nはデータの個数、xiは各データの値、x barは標本平均(3)標本標準偏差 標本自体のばらつきの大きさを表す。 標本分散の平方根が標本標準偏差。  |
||||
| 標準誤差(standard error、SE) | ||||
| 母集団からある数の標本を選ぶとき、選ぶ組み合わせに依って統計量がどの程度ばらつくかを、全ての組み合わせについての標準偏差で表したものをいう。 標準偏差と混同しやすいですが、標準偏差は標本自体(あるいは標本から推定された母集団、または単に母集団)のばらつきを表すのに対し、標準誤差は標本から得られる統計量がどの程度のばらつきを持っているかということを表している。 つまり、標準誤差は「母集団の統計量に対して、標本から得られる統計量がどのくらいばらつくか」を示し。 この式で重要なのは、標準誤差は抽出する標本数の平方根に反比例するという点である。 つまり、例えば標本数を4倍にすると標準誤差を半分にできる。 統計調査を計画する際に、費用や手間をある範囲内に収めた上で誤差を最小にしたい場合が多い。 これらの条件の関係を判断するのに上の関係式が重要となる。 |
||||
| 中央値(median) | ||||
| 中央値とは データを小さい順に並べたときの中央の値。 データ数がnの時、中央値は次の式で表される。 中央値は平均値と類似した目的で使うが、用途によっては中央値のほうが平均値よりも優れている。 例えば、{9,5,8,6,1}の中央値は5となる。 平均値との関係 データの分布が対称である場合は、中央値は平均値に等しい。 ただし、分布が対称でなくても、中央値と平均値が等しくなる事もある。  ここで、xnはn番目に大きいデータを表す。 |
||||
| 最頻値(mode) | ||||
| モード (mode)、並み数 ともいう。データのうち、度数分布において最も高い度数を示す値。 つまり最も多く現れているデータの値。 例えば、{9,5,8,6,1,10,9,2}の最頻値は9となる。 |
||||
| 最大値・最小値 | ||||
| 数値データにおいて、データを昇順にソートしたとき、最初の値を最小値、最後の値を最大値と呼ぶ。 |
||||
| 参考資料 | ||||
| 「統計学要論」 (共立出版 1975) 「バイオサイエンスの統計学」 (南江堂 1994) 「医学・公衆衛生学のための統計学入門」 (南江堂 1988) 「図解 確率・統計の仕組みがわかる本」 (技術評論社 2008 長谷川勝也) 「Excelでここまでできる統計解析」 (日本規格協会 2007 今里健一郎 森田浩) 「エビデンス主義 統計数値から常識のウソを見抜く」 (角川SSコミュニケーションズ 2009 和田秀樹) |
||||
|
||||